
Research Data Management
What is Research Data Management?
Section titled “What is Research Data Management?”Research Data Management (RDM) combines conceptual, organizational, and technical measures and practices for handling your research data during its evolution in a way that other researchers can find, understand, and ultimately, reuse them. RDM strategies can greatly vary between domains or even data types. Hence, an approach for unification, ideally for all scenarios, would be highly desirable. For plant sciences, it is widely accepted to divide RDM into a data life cycle with different phases, i.e. planning, collecting, processing, analysing, preserving, sharing, and reusing your research data. This also includes how your data will be handled after a project has ended, e.g. long-term storage of and access rights to the data. DataPLANT, and this Knowledge Base, aims at supporting you during these phases and thereby, in the FAIRification of your data.
Research Data Life Cycles
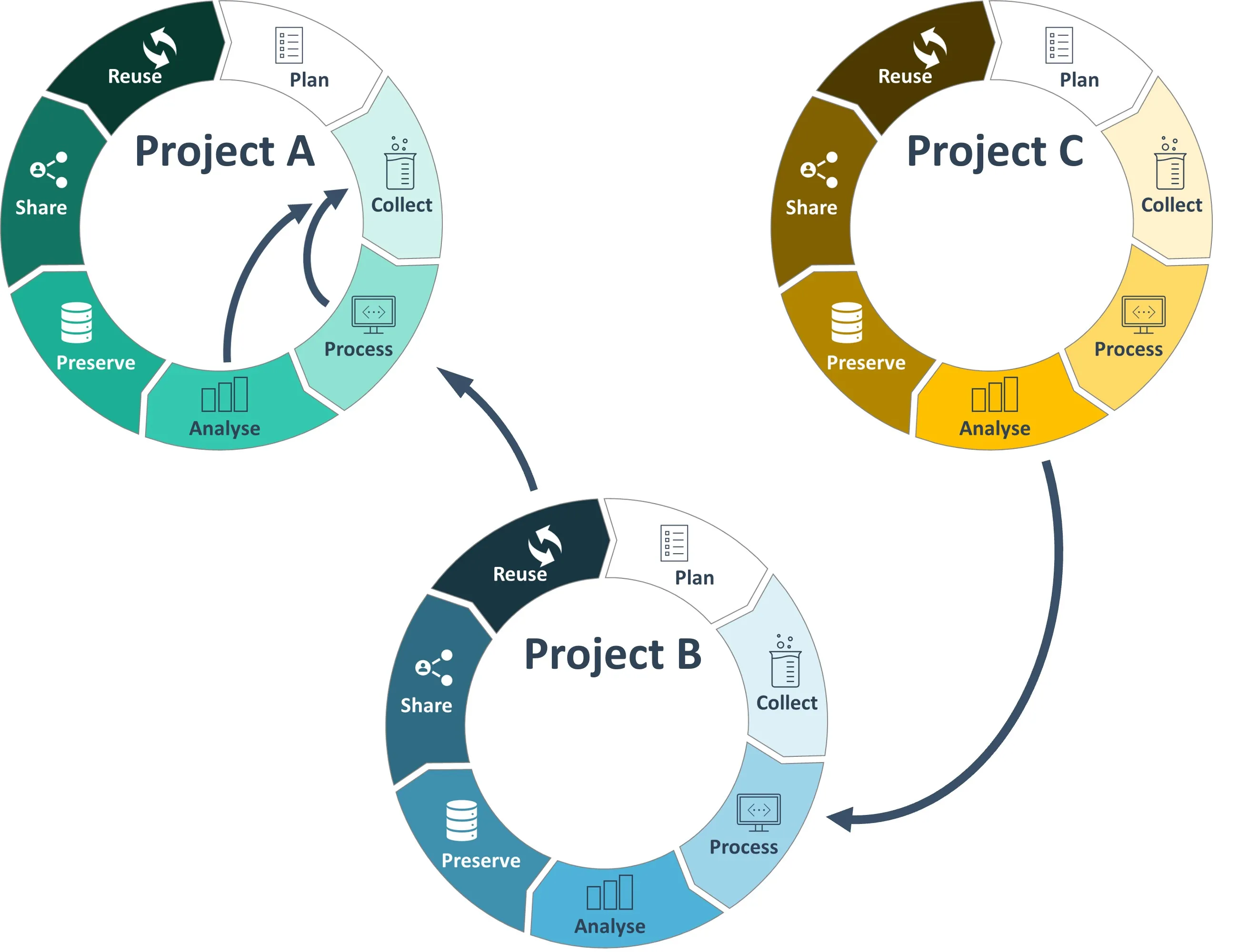
Section titled “Research Data Life Cycles”For plant sciences, we would like to complement the concept of the data life cycle with the aspect of multiple connections between and iterations within the cycle. These additions mirror the evolution of data, as research data are not static, can build on each other, and sometimes might call for a re-evaluation. In some scenarios you might need to jump back to data collection after you made a breakthrough during your analyses. In another case, you might think that it would be helpful to process older data with different tools or a distinct focus as your results gave you new insights.
Data management planning represents the phase of defining your strategy for managing data and documentation generated within the project. In this phase you try to anticipate the best ways to avoid problems and setting the conditions for your research data to achieve the highest possible impact in science, even after project completion. This can, e.g., involve standards or best practices. The outcomes of your planning, including aspects of the data management process before, during, and after the end of a project, is usually formalised in a Data Management Plan (DMP), which is often required by research organisations and funders.
The data collection phase is the time to gather information about specific variables of interest, e.g. in plant sciences the expression of a certain protein under stress conditions. While data collection methods strongly depend on the field and research subject, it is always important to ensure data quality. You can also use already existing data in your project. This can either be previously collected datasets or consensus data, such as a reference genome. For more information see also Reusing.
Besides data quality, the collection phase also determines the quality of your documentation, including the provenance of samples, researchers or instruments. This serves the purpose to make your data understandable and reproducible. Tools or the integration of multiple tools (also called tool ecosystem) can assist you in data management and documentation during data collection.
During this phase of your project, you convert your data into a desired format and prepare it for analysis. Ideally, data processing includes some automated, yet oftentimes still partially manual, steps in a workflow, which help you in evaluating the quality of your data. The main goals are to convert your data into a readable format needed for downstream analysis in order to create clean, high-quality datasets for reliable results. When data is imported from existing sources, e.g. data to be reused from another project, processing can also include manual steps to make it suitable for analysis. Accurate data processing is also essential for combining two or more datasets into a single dataset. Again, a high-quality documentation during data processing is key to ensure reproducibility of your results.
Data analysis follows the (often automated, batch) data processing stage. It consists of exploring your data to identify or understand relationships between variables by applying mathematical formula (or models). Steps of the analysis workflow are oftentimes repeated several times to iteratively optimize the workflow for data exploration. Your data analysis methods will differ depending on the type of your data (quantitative or qualitative).
The data analysis part of a project is often considered as central, as you generate new knowledge and information at this stage. Due to the relevance of the data analysis stage in research findings, it is essential that your analysis workflow complies with the FAIR principles. Precisely, this means that the workflow is reproducible by other researchers and scientists.
The process of data preservation represents a series of activities necessary to ensure safety, integrity and accessibility of your data for as long as necessary, even decades. It prevents data from becoming unavailable and unusable over time through appropriate actions and therefore, is indeed more than just data storage and backup. Such activities can include that the data is organised and described with appropriate metadata to be always understandable and reusable. Main reasons for research data preservation are to guarantee verification and reproducibility for several years after the end of a project, allow reuse of your data, or a requirement by funders, publishers, institutions, or organisations for a specific purpose, such as teaching or research building on the findings and conclusions.
Sharing is not limited to publishing your data to share it with the global research community. This can also mean to send your data to collaboration partners in the context of a collaborative research project. It is important to know that data sharing is not equal to open data or public data, as you can also choose to share your data with defined access rights. You can share your data at any time during the research data life cycle but the data should be available at the time of a publication of articles that use the corresponding data to make scientific conclusions. For more information see also Data Sharing.
Reuse of data is particularly important in science, as it drives research by enabling different researchers (or yourself) to build upon the same data independently of one another resulting again in new, maybe unanticipated, uses for the data. Reusability is one key component of the FAIR principles. By reusing data you can also avoid doing unnecessary experiments for data that has already been published or verify reported findings as correct, laying a robust foundation for subsequent studies.