Data Publications
last updated at 2022-05-19Publishing research data allows others to access and use your data. Writing a manuscript can consume a lot of time. Some researchers might find this process tedious if they only want to publish certain data, which they considered as interesting or impactful during and after collection. Data publishing is an integral part of the open science movement. In general, the main goal of data publishing is to evolve data to first class research outputs, driven by a number of initiatives. This enables datasets to be cited similarly to other research publication types, such as articles or books, enabling producers of datasets to gain academic credit for their work.
The motivations for publishing data may range from a desire to make research more accessible, making datasets citable, or research funders or publishers require open data publishing. Some scientists might argue that they would feel uncomfortable about publishing their dataset, as it could allow people to use their work from the web and extract novelties out of it. However, most print-based science journals are available online nowadays, so the potential of exploiting is already present. Additionally, solutions to preserve privacy within data publishing has been proposed, including privacy protection algorithms, data ”masking” methods, and regional privacy level calculation algorithm. In general, the advantages of data publications prevail. Here is a list of some potential benefits you might get from publishing your dataset:
- Data can be reused for similar and new purposes
- Data can be integrated with other data to create new data resources - Invitations to collaborate
- Invitations to provide consultancy
- Greater citation rate
- Citation of data publications is likely to increase citations of related research papers
- Wider recognition among peers
- Overall acceleration of science and better science
- Data protection: once it’s published, with provenance and DOI (a) the data is safe (backed-up) at an additional storage site and (b) as a researcher I can prove it’s mine
- ...
There are a several criteria to consider during publication of your dataset:
- Of course, your data needs to be hosted in a repository to make it available for everyone. Various repositories exist, which have been developed to support data publication, e.g. Zenodo, including general, but also domain-specific data repositories exist.
- Your dataset needs to be well annotated, allowing other researchers to understand and reuse your data (see also metadata).
- Your dataset needs to be assigned a persistent identifier (PID), such as a DOI. This can be assigned directly on the repository or with the help of a publication service, such as Invenio. The identifier will others to cite your dataset.
- If the publisher validates your data, your metadata annotation is reviewed to ensure comprehensibility. There is also the possibility for publishing a data paper about the dataset, which may be published as a preprint, in a journal, or in a data journal that is dedicated to supporting data papers. The data may be hosted by the journal or hosted separately in a data repository.
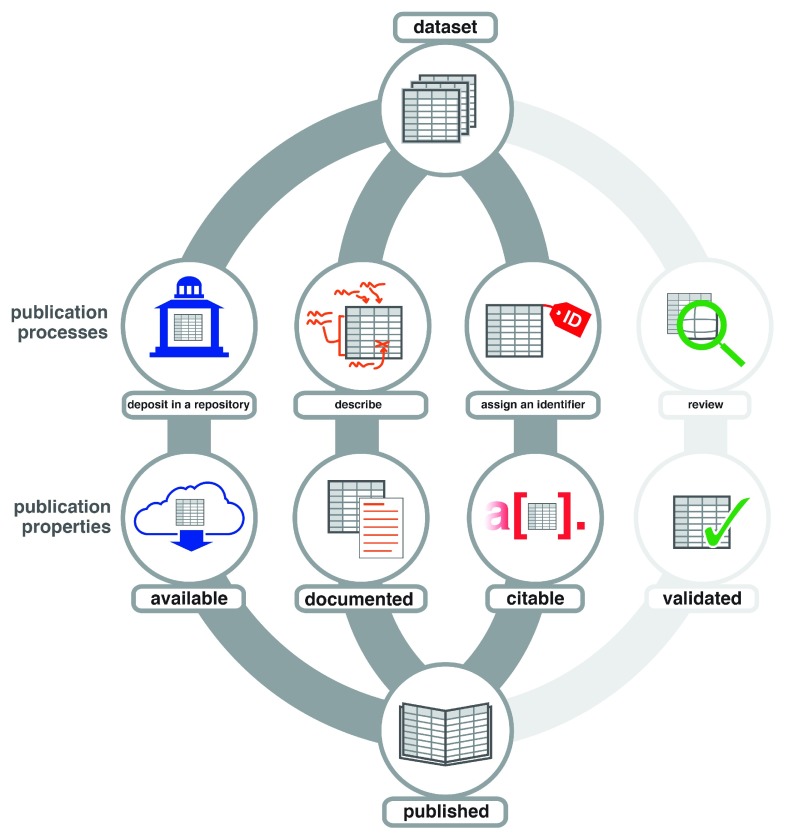
Figure 1: During publication, datasets are typically deposited in a repository to make them available, documented to support reproduction and reuse, and assigned an identifier to facilitate citation. Some, but not all, publishers review datasets to validate them.
Data papers or data articles are “scholarly publications of a searchable metadata document describing a particular on-line accessible dataset, or a group of datasets, published in accordance to the standard academic practices”. The intent of a data paper is to offer a descriptive information on the related dataset(s) focusing on data collection and distinguishing features, rather than on data processing and analysis. Thereby, their aim is answering questions like “What data was published?”, “How was the data collected?”, or “Who collected the data?”. As data papers are considered academic publications, just as other types of papers, they allow scientists sharing data to receive credit and thus, upgrading the value of data sharing. This provides not only an additional incentive to share data, but also increases metadata quality and reusability of the shared data.
Data papers are supported by a variety of journals, of which some are “true” data journals, i.e. they are dedicated to publishing data papers only, while the majority are mixed journals meaning they publish a number of article types, including data papers. A comprehensive list of data journals for different domains can be found here.
The following table gives an overview about DataPLANT tools and services supporting you in data publishing. Follow the link in the first column for details.
| Name | Type | Tasks on metadata |
|---|---|---|
| DataHUB | Service | Share:
|
| Invenio | Service under construction | Share:
|
| Metadata registry | Service under construction | Share:
|
| Converters | Tool under construction | Curate:
|
- Data publication: towards a database of everything
- Motivating Online Publication of Data
- Data publication consensus and controversies
- Making Data a First Class Scientific Output
- The data paper